
Desktop Survival Guide
by Graham Williams
|
|
DATA MINING
Desktop Survival Guide by Graham Williams |
|
|||
|





|
Todo: UNDER CONSTRUCTION
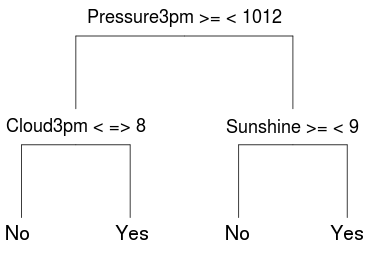
In this chapter we discuss the decision tree structure as a knowledge representation language (Section 12.1). A heuristic search algorithm is presented for finding a good decision tree in Section 12.2. The measures used are discussed in Section 12.3. Section 12.4 then illustrates the building of a decision tree in Rattle and directly through R. The options for building a decision tree are covered in Section 12.5.