Desktop Survival Guide
by Graham Williams
|
|
DATA MINING
Desktop Survival Guide by Graham Williams |
|
|||
Evaluating the Model: Error Matrix |





|
Having explored our data to gain insights into its shape, and, in all likelihood, also having transformed and cleaned up our data in various ways, we have also illustrated how to build our first model. It is time to evaluate the performance or quality of the model.
Evaluation is a critical step in any data mining process, and one that is often left under done. For the sake of getting started we will look at two simple evaluations. One, the error matrix (also often called the confusion matrix), is a common mechanism for evaluating model performance. The other, a risk chart, provides a visual indication of performance.
In building our model we used a 70% subset of all of the available data. Figure 2.3 illustrates the default sampling strategy of 70%/15%/15%. We call this 70% sample of the whole dataset the training dataset. The remainder is further split into a validation dataset (15%) and a testing dataset (the remaining 15%).
The validation dataset is used to test different parameter settings or to test different choices of variables whilst we are data mining. This It i similarly important to note that this dataset should not be used to provide any error estimations of the final results from data mining, since it has been used as part of the process.
The testing dataset is only to be used to predict the unbiased error of the final results. It is important to note that this testing dataset is not used in any way in building or even fine tuning the models that we might build as we progress through the data mining project.
The testing dataset and, whilst we are building models, the validation dataset are used to test the performance of the models we build. This often involves calculating the model error rate. An error matrix simply compares the decision made by the model with the actual decisions. This will provide us with an understanding of the level of accuracy of the model--that is, how well will the model perform on new, previously unseen, data.
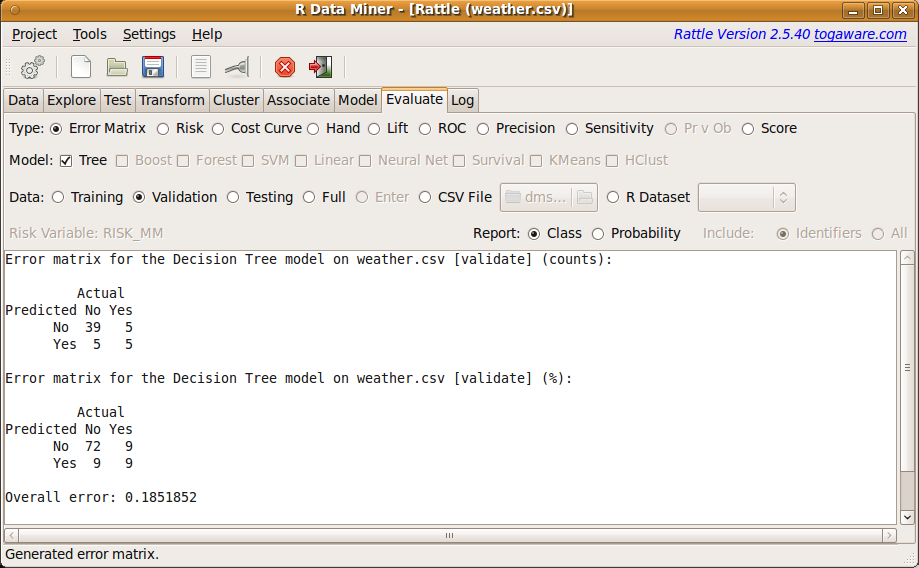
Figure 2.8 shows the Evaluate tab with the Error Matrix for the Tree model shown in Figures 2.4 and 2.5. Two tables are presented, one listing the actual counts of observations and the other the percentages. We can see that the model correctly predicts that it won't rain for 72% of the days that the model was applied to (called the true negatives) or 39 days out of 54 days are correctly predicted as not raining. Similarly we can see that the model is correct in predicting rain (called the true positives) for 9% of the days.
We note that there will be 5 days when we are expecting rain and none occurs (called the false positives. If we were using this model to help us decide whether to take an umbrella or rain coat with us on our travels tomorrow, then it is probably not a serious loss in this circumstance. We had to carry an umbrella without needing to use it. Perhaps more serious though is that there are 5 days when our model tells us there will be no rain, yet it rains (called the false negatives). We might get inconveniently wet without our umbrella.
The concepts of true and false positives and negatives will be further covered in Chapter 22.
The performance measure here tells us that we are going to get wet more often than we would like to. This is an interesting issue--the fact that the different types of errors have different consequences for us. We'll see more about this in Chapter 22.
It is useful to compare the performance as measured using the
validation dataset with the performance as measured using the training
dataset. To do so we can select the Training option from
the Data line of the Evaluate tab, and
Execute that. The resulting
performance will be reported. We reproduce both here for
comparison. Both the count and the percentages are presented.
| Count | Actual | ||
| No | Yes | ||
| Predict | No | 205 | 15 |
| Yes | 10 | 26 | |
| Percentage | Actual | ||
| No | Yes | ||
| Predict | No | 80 | 6 |
| Yes | 4 | 10 | |
| Count | Actual | ||
| No | Yes | ||
| Predict | No | 39 | 5 |
| Yes | 5 | 5 | |
| Percentage | Actual | ||
| No | Yes | ||
| Predict | No | 72 | 9 |
| Yes | 9 | 9 | |
| Count | Actual | ||
| No | Yes | ||
| Predict | No | 35 | 5 |
| Yes | 6 | 10 | |
| Percentage | Actual | ||
| No | Yes | ||
| Predict | No | 62 | 9 |
| Yes | 11 | 18 | |
We can see that there are much fewer errors on the training dataset than either the validation and testing datasets. That is not surprising since the tree was built using the training dataset, and so it should be more accurate on what it has already seen. This provides a hint as to why we do not validate our model on the training dataset--the evaluation will provide optimistic estimates of the performance of the model. By applying the model to the validation and testing datasets (which the model has not previously seen) we expect to obtain a more realistic estimate of the performance of the model on new data.
Todo: Talk about how validate and test differ a little, since we have small datasets the high variation is expected.