Desktop Survival Guide
by Graham Williams
|
|
DATA MINING
Desktop Survival Guide by Graham Williams |
|
|||
Usage |





|
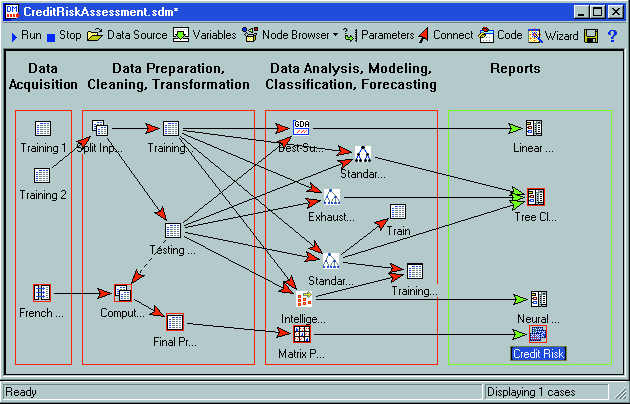
STATISTICA Data Miner implements a large number of algorithms for analysing data. They are seamlessly integrated with other analytic and graphics options within an icon based used interface.
The graphical user interface allows analysis nodes to be dragged into the data mining workspace and connected to other nodes. Results can be reviewed, analysed, and saved, or used to perform additional interactive analyses. The analysis nodes can handle multiple data streams, enabling processing of lists of data sources. STATISTICA includes options for defining connections to databases on remote servers.
A particularly significant feature of STATISTICA is its open architecture which allows users to add their own custom nodes implemented in any language accessible from Visual Basic programs. User supplied nodes can have their own user interface for accepting user parameters, choices, etc. The resulting node then becomes part of the toolkit available to your users.
Multi-threading and distributed processing allows multiple servers to work in parallel for computationally intensive projects. STATISTICA Data Miner is also a COM object allowing full integration with other applications or analysis macros under MSWindows.
A comprehensive collection of algorithms is implemented in STATISTICA Data Miner. These include statistical, exploratory, and visualisation techniques. In addition to the techniques listed in the summary above, graphical and interactive exploration/visualisation tools work with descriptive statistics and exploratory data analysis to give initial insights into the data being explored. General data mining operations, including slice and dice and drill-down, for interactively exploring data on selected variables and categories are also supported.
A goodness of fit module computes various goodness of fit statistics for continuous and categoric output variables (for regression and classification problems). The module provides a competitive evaluation of models, as a tool to choose the best solution.
The Predictive Modelling Markup Language (PMML) is supported as the description language for generated models from many of the included predictive data mining tools. PMML, based on XML, allows both sharing of models and loading of other, possibly externally generated, models into STATISTICA.